




Process control and optimisation: on commonalities between methodologies
By Rob Meier (https://www.linkedin.com/in/robert-meier-b81169a/)
Plant(-wide) process optimisation approaches using current methodologies have mutual differences but also clear commonalities.
The scientific community often feels split into the different camps, sometimes it is really like that, but actually they also have important things in common. One major commonality, although a pretty obvious and perhaps just a trivial one, is that all models are based on mathematical representations, see also Post by Matti Vilkko.
The one methodology uses physical models, so equations that describe the process using differential equations and so on. These are often available from the past, built using tools like, e.g., ASPEN. A larger part of the current community likes these models because it is argued these are based on scientific understanding, and that is correct as such. However, these models have often been built to describe the process, and it has been validated it does, but it does not automatically imply these are appropriate to predict with the aim to optimize in the best possible way.
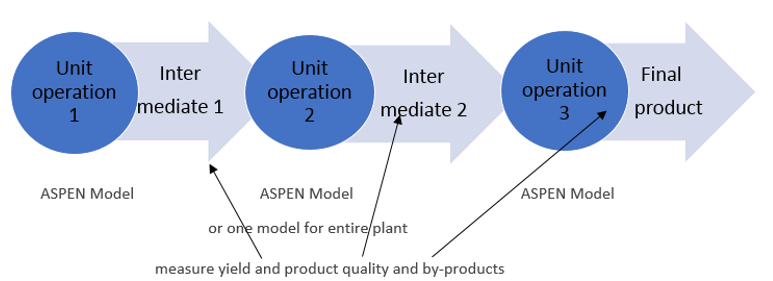
The other main class of models are the data-driven models. Plant data are being used to construct a model using, e.g. A(rtificial)I(ntelligence) methods such as Neural Network (NN) analysis, see the scheme below indicating that in such models we make a direct link between process input data (temperature, pressure, flow rates, feedstock, ….) and output parameters such as quality and yield.

A second commonality in all approaches is that we need plant data to build the model. For a physical model this is once, and after that the model is normally used as such. Of course, there are also models that originate from the design phase, but such models cannot be expected to describe the plant with the accuracy required for optimisation purposes as we discuss in COCOP. For the other class, let us assume we use a Neural Network model, we need the data to be able to build the model directly between input and output parameters. When more data come available in course of time, the model can be easily updated by rerunning the script used to build the model first time.
A third commonality is the fact that the completeness and integrity of the data need to be checked, and erroneous data deleted (see also Post by Norbert Link and Norbert Holzknecht). On integrity, with the current state of affairs, one often has to put together data ‘by hand’, next put them in one file before a model can be constructed. This is obviously prone to human errors. But also, when the procedure of collecting data is fully automated, one of the goals of the COCOP design (see Post by Petri Kannisto and David Hästbacka), erroneous data come into the data set due to failing sensors or other reasons. When a model is built and then applied, without a real-time update, tools are applied to check on erroneous data and subsequently delete these. Still, one may argue that when smaller deviations are discussed as potential erroneous data, it is necessary to have a very reliable tool to ensure that no potentially valuable data are deleted as they are considered outliers. When in future implementations are used that involve real-time model updating this might become a challenging problem.
Regarding completeness, we refer to whether we have sufficient information to arrive at a good predictive model. There are at least two main aspects here. The first one is whether we have sufficient data on the product specification side to allow for a good model. A lot of parameters are measured quasi continuously in a plant, but the products specifications are often not measured with that high frequency whereas it is often known that variations in the process happen during the day or multiple days. Without the guarantee that we will have sufficient data, here referred to as complete as we have a lot of data but the products specs might be missing to a large extent, a model aiming at predicting 1-10 % increase in performance is doomed to fail. In that case adding further sensors or decreasing products quality analysis intervals would be a high priority.
A further topic is the (non-)linearity of the problem. One has to take into account that we are dealing with non-linear behaviour, at least of a number of variables (see also Post by Matti Vilkko). In the past linear models were often the standard, also for Model Predictive Control. However, more recent development are fostering non-linear MPC control theory (see Post by Jörgen K H Knudsen), whereas Artificial Intelligence models like Neural Networks are inherently accounting for, even high, non-linearities.
Sometimes assumed differences might, in reality, have to do more with semantics, even though practical implementation might still be different. Model Predictive Control when visualized, as in the figure below, is at this level not much different from NN models, perhaps one could say that for some cases the NN model actually is a MPC based system. What is written in Post by Jörgen K H Knudsen also very well fits what is done when applying NN based modelling.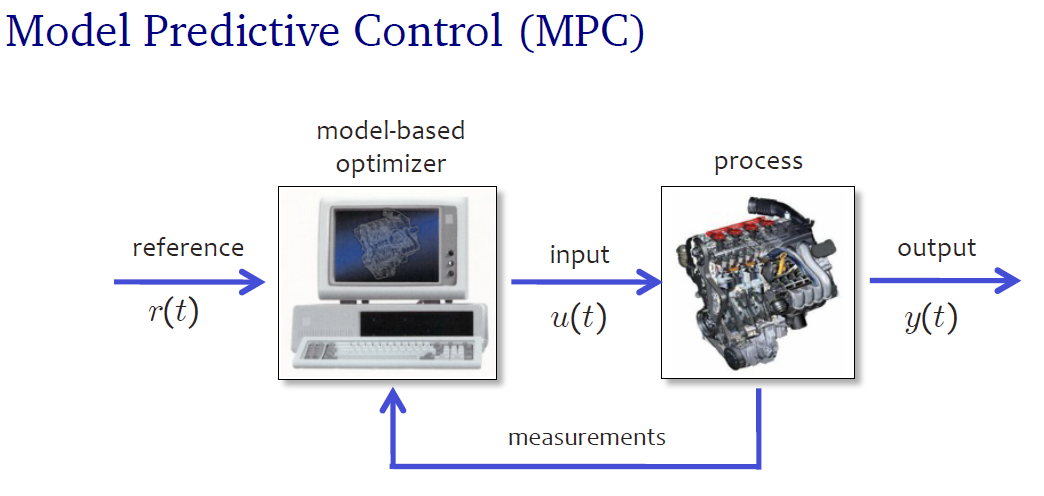
(taken from http://cse.lab.imtlucca.it/~bemporad/teaching/ac/pdf/AC2-10-MPC.pdf)
In my view, it will largely depend on the process and the actual demands (what needs optimized, etcetera) which model will be most appropriate
Follow the discussion in the COCOP Debate Group of Linkedin

")
")
 (MSI)")
")

")
